要使用DITA来制作文档,必须要有工具,毕竟DITA本身只是XML文件,离真正好看的文档还有距离,这就是它的工具链。
三大功能:编辑、处理、管理
DITA本身就是XML,所有文本编辑器都可以编辑。为了方便,可以用一些有XML支持的编辑器,如Notepad++。如果想更加方便,尤其是在企业环境下,最好还是用专门的工具,如:
- Arbortext Editor (http://www.ptc.com/)
- Oxygen (http://www.oxygenxml.com/)
- XMetal (http://www.justsystems.com/)
- Syntext Serna (http://www.syntext.com)
- Adobe FrameMaker 11以上
但是单独一个编辑环境,并不能完成输出的工作(FrameMaker可以按预设的模板输出成PDF)。要想输出还得有处理工具,这就是工具开发的主要工作。如果想体验一下,可以用DITA Open Toolkit (http://www.dita-ot.org/)。
还有一些支持DITA的CMS,可以用来管理文档:
- EMC Documentum
- PTC Windchill
- EasyDITA.com
当然,编辑,处理,管理这三大功能不一定完全这么分开,一个系统完全可以涵盖所有三个功能。几大技术文档方案提供商都有全套的方案。
可能的DITA工具链
- Basic and free: XML editor + Version control + Open Toolkit
- Reasonable: FrameMaker + Version Control + Open Toolkit/Robohelp
- Easy and a whole solution: EasyDITA.com, web-based solutions
- Advanced solution: Arbortext Editor + Styler + Content Manager + Publishing Engine
DITA-OT
DITA-OT是一套开源的DITA工具,使用Java写的,可以处理DITA文件,来输出成为HTML/CHM/PDF等文档。基本的思路就是用XSLT或XPath去读取XML,然后给特定的句了或段落加上特定的格式或者至少是Tag,然后如果是HTML类的输出,就用CSS之类的样式来格式化,如果是PDF的输出,就不光要给它加上格式,最重要的是写成页面。
DITA-OT里面输出PDF页面用的是FOP,全称是Fomat Object Processor,Format Object也是一套特殊的页面排版语言,还是在XML的领域内,称为XSL-FO,这处文件再用一个FOP来处理,就可以输出成为真正的排好版的页面PDF。
可以看出来,这里这个FOP是核心技术。描述一个页面及其排版还是比较容易,但真正把内容放到一系列页面上,则有相当的工作要做。DITA-OT里面自带一个开源免费的FOP,Apache组织在维护的,它输出页面没有问题,但是不能生成索引Index。
同时,还有商业的FOP可以用,如XEP的,个人可以免费注册后下载使用,它可以输出Index,页面也不错,但是免费版会打上水印。
DITA-OT的工作流程
工作流程如下图:
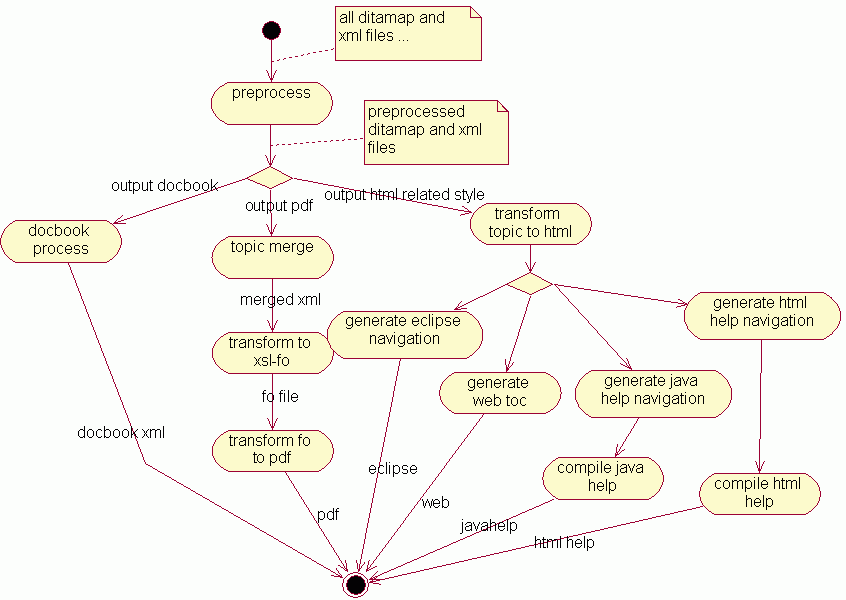
DITA-OT样式设计所需要的知识
- XML
- CSS
- XSL,XSLT/Xpath
- XSL-FO
- Java
和XML相关的知识都可以在 http://www.w3schools.com/ 网站上学个初步。
相关资源
- http://www.dita-ot.org/ DITA open toolkit develop website
- http://dita.xml.org/ DITA XML focus website
- http://tech.groups.yahoo.com/group/dita-users/ DITA-users group, a mailing list with searchable archive
- http://docs.oasis-open.org/dita/v1.2/spec/DITA1.2-spec.html DITA specification
- http://dita.xml.org/resource-directory DITA resources
- http://www.ditausers.org/tutorials/ online tutorials
- http://www.scriptorium.com/whitepapers/hackingot/ Hacking DITA OT
- 图书: DITA Best Practices (DITA最佳实践指南,北京:科学出版社,2012.11)
声明:
本文档是两年前记录,主要针对DITA-OT 1.7/1.8,对于最新的发展没有关注,也没有测试。
本文档真正有用的东西也仅限PDF输出,其他的输出没有涉及。